могут все
Устал пыхтеть на работе? Заходи - здесь Мы рассказываем про заработок в интернете в 2025 году, попробуй его в действии.
Кто сказал, что доски объявлений не работают? Если вы не знали, то большая часть ваших клиентов как раз и ищут, то, что вы продаёте именно здесь.
 Большая база досок объявлений, состоящая из 471 штуки;
Большая база досок объявлений, состоящая из 471 штуки;Регистрация занимает 17 минут;
Ты сможешь сам распределять время подачи объявлений.
Всего досок объявлений: 471
Участников системы: 573469
Сегодня новых: 893
Вчера: 1386
Напоминаем, что добавить объявление в нашу базу досок вы можете за 79 рублей. Мы гарантируем качество.
Трастовые белые каталоги – это ценность для любого размещаемого сайта, за счёт повышения трастовости ресурса и поведенческих факторов.
 Собственная база из 2183 белого каталога статей с ТИЦ от 30;
Собственная база из 2183 белого каталога статей с ТИЦ от 30;Ты вправе сам распределять время размещения своих статей;
Ты ещё думаешь?
Всего каталогов статей: 2183
Участников системы: 473964
Сегодня новых: 692
Вчера: 981
Напоминаем, что добавить статьи в наши каталоги статей вы можете за 379 рублей. Мы гарантируем качество.
79 рублей привлечь клиентов с помощью нашего сервиса!
регистрация

Если вы ещё думаете, что новому сайту не нужна регистрация в каталогах статей или досках, то это 100% заблуждение. Как показывает наша статистика, более 87% вновь добавленных сайтов в нашу систему, начинают эффективно индексироваться в Яндексе и Гугле уже спустя пару дней, а уже через 5-9 дней имеют подъём по НЧ запросам в поисковых системах, например, таких как Гугл..
База предлагаемая для регистрации была вручную отобрана и относится к 4-му кварталу 2018 года, так что советуем воспользоваться нашим сервисом для регистрации не только на досках объявлениях, но и так же в тематических каталогах статей.
Этапы регистрации в нашем сервисе
 Банальная регистрация
Банальная регистрацияв системе, дабы завести себе аккаунт. Наверно особо писать здесь нечего. Спасибо.
Двигаемся далее
 Создаём проект,
Создаём проект,наполняем его информацией для успешной регистрации. Указываем свой сайт.
Двигаемся далее
 Процесс регистрации
Процесс регистрациинапоминает взлёт ракеты, где отчёт регистрации показан в процентах.
Поехали?
 Получаем полный отчёт
Получаем полный отчёто всех добавленных объявлениях. Пожалуй это самая приятная часть.
Наслаждаемся бэками
Маркетинг 2016 года
Как ускорить сбор семантического ядра?
Думаю, что у каждого, кто сталкивался со сбором семантического ядра, появлялась мысль: «Как же долго и нудно идет парсинг, надоело перебирать и группировать тысячи этих запросов!». Это нормально. У меня тоже такое бывает иногда. Особенно, когда приходится парсить и перебирать СЯ, которое состоит из нескольких десятков тысяч запросов.
Перед тем, как приступить к парсингу, настоятельно советую вам разбить все запросы на группы. К примеру, если у вас тематика сайта «Строительство дома», разбейте её на фундамент, стены, окна, двери, крышу, проводку, отопление и т.д. Вам просто потом будет намного легче перебирать и группировать запросы, когда они будут расположены в небольшой группе и связаны между собой определенной узкой тематикой. Если же вы просто будете парсить все в одну кучу, у вас получится нереально огромный список, на обработку которого уйдет не один день. А так, обрабатывая весь список СЯ небольшими шагами, вы не только более качественно проработаете все запросы, но и сможете параллельно заказывать у копирайтеров статьи для уже собранных ключей.
Процесс сбора семантического ядра у меня практически всегда начинается с автоматического парсинга запросов (для этого я использую Кей Коллектор). Вручную тоже можно собирать, но если мы работаем с большим количеством запросов, я не вижу смысла тратить свое драгоценное время на эту рутинную работу.
Если вы работаете с другими программами, то в них, скорее всего, будет доступна функция работы с прокси-серверами. Это позволяет ускорить процесс парсинга и обезопасить свой IP от бана поисковиков. Честно говоря, не очень приятно, когда нужно срочно выполнить заказ, а твой IP из-за частого обращения к сервису статистики Гугла/Яндекса банят на сутки. Вот в этом случае и приходят на помощь платные проксисервера.
Лично я в данный момент не использую их по одной простой причине – их постоянно банят, найти качественные рабочие прокси не так то и легко, да и лишний раз платить за них деньги у меня нет желания. Поэтому я нашел альтернативный способ сбора СЯ, который в несколько раз ускорил этот процесс.
1. Регистрируемся в http ://antigate.com . Он нам понадобится для автоматического распознавания каптчи, которая постоянно появляется во время парсинга. Стоимость 1000 загруженных каптч – 1$. На первое время вам этого с головой хватит.
После того, как пополните счет в системе, скопируйте ключ доступа и вставьте его в Кей Коллектор.
2. После этого в настройках Кей Коллектора делаем следующие настройки. Ускорение сбора данных позволяет использовать онлайн базу ключевых слов, которая есть в Кей Коллекторе.
Таймаут ожидания сервиса – 8000 мс. Если у вас плохая скорость интернета, установите это значение больше (но не более 30000 мс).
Вот что об этом параметре говорится на сайте Кей Коллектора:
Помимо пауз между запросами (обычными таймаутами) существует понятие таймаута ожидания ответа от сервиса. Это тот период времени, который программа будет ждать ответа на отправленный в сервис запрос, прежде чем сообщит в журнале событий об ошибке и не перейдет к следующей фразе или не совершит повторный запрос.
Данный параметр может пригодиться, если Вы имеет плохое качество соединения с Интернетом или используете некачественные прокси-сервера.
Внимание: мы не рекомендуем устанавливать значение меньше, чем 3 000 мс, т.к. большинство запросов будет прерываться раньше, чем их обработает сервис. Также мы не рекомендуем использовать задержку больше 30 000 мс, т.к. с большой долей вероятности можно утверждать, что если сервис или прокси не ответили в течение 30 секунд, то ответ не придет и через 60. Согласно нашим экспериментам оптимальным значением будет 8 000 - 16 000 мс.
Внимание: при установке данного параметра следует учитывать не только качество используемых прокси-серверов, но и скорость доступа в сеть и количество потоков. Например, даже при использовании самых качественных прокси-серверов, программа не будет успевать получить ответ от сервиса, если скорость доступа в сеть на каждый поток будет слишком маленькой.
Во вкладке Yandex.Wordstat у меня следующие настройки.
Добавлять в таблицу фразы с частотностью от 10 – если у вас не очень узкая ниша, то советую указать это в настройках. Таким образом, программа не будет тратить время парсинг «запросов-пустышек».
Не снимать частотности для фраз с базовой частотностью равной или ниже 10 – таким образом можно сократить время на собрание уточняющих частотностей вида «» и «!».
Кол-во потоков 1 – так как я работаю на одном IP (к тому же, основном), лучше работать только в 1 потоке.
Тайм-аут ожидания – 8000 мс.
Обновлять статистику для существующих в таблице фраз при пакетном сборе фраз таким образом мы экономим время сбора базовой частотности для фраз в таблице, добавленных из различных источников. Если вы работаете с очень большими проектами, лучше выключить эту опцию.
Получать частотности из APIShops.com - регистрируемся в сервисе, пополняем баланс, вводим свой логин и пароль в Кей Коллекторе и получаем данные о частотностях без капчи и задержек без обращений к Yandex.Wordstat.
Сервис предлагает 3 вида съема частотностей (БЕЗ УЧЕТА РЕГИОНОВ!):
a. получение для переданных фраз имеющейся в системе частотности (без заказа проверок) — бесплатно (данные могут быть устаревшими);
b. получение для переданных фраз имеющейся в системе частотности, а также заказ проверки частотности для отсутствующих в системе фраз — 5 руб. за 1000 фраз;
c. заказ проверки частотности для всех переданных в запросе фраз — 5 руб. за 1000 фраз.
При этом повторная проверка фраз в течение двух суток с момента списания средств осуществляется бесплатно.
На данный момент APIShops дает каждому зарегистрировавшемуся пользователю бонус 5$, чего хватает на 30000 бесплатных проверок.
Функцию APIShops можно использовать, но она имеет свои недостатки (частотности для всех запросов не снимаются). Поэтому, можете поэкспериментировать с ее функционалом, но я все же советую не использовать её во время парсинга. Ниже, в 4м пункте, я расскажу об альтернативном, более лучшем, работающем методе.
Кроме этого, если вы работаете с большими проектами, советую отключить обновление содержимого таблицы после групповых операций вставки и обновления при парсинге.
3. Ускорение сбора семантического ядра при помощи удаления неявных дублей.
Этот шаг нужно выполнять после того, как вы выполнили парсинг запросов и их базовой частотности. Открываем в Кей Коллекторе вкладку «Данные – Анализ неявных дублей».
На примере сайта, который занимается продажей эротического белья.
Закрываем окно. Теперь в общей таблице с запросами выделено по 1му дублю фразы. Выбираем «Данные – Удалить фразы». Не будем тратить время на сбор данных для дублирующих запросов. Если у вас СЯ на несколько десятков тысяч запросов, то ваш список запросов «станет легче» на несколько сотен ключевиков.
4. А теперь перейдем к наиболее важной настройке, которая позволит вам анализировать до 1000 фраз за 1 минуту в одном потоке.
Открываете «Настройки - Парсинг - Yandex.Direct», указываете в нем несколько аккаунтов Yandex.Direct и сохраняете изменения. Несколько аккаунтов нужны для того, что они периодически банятся Яндексом.
Внимание! Ни в коем случае не указывайте свои настоящие аккаунты. Создайте для парсинга отдельные профили.
Открываем проект с запросами, частотность которых нужно проверить и нажимаем на кнопку Яндекс Директа.
Целью нашей задачи является съем частотностей Yandex.Wordstat, поэтому нужно активировать соответствующую опцию в окне запуска – «Целью запуска сбора статистики является заполнение колонок частотности Yandex.Wordstat».
Указываем формат «!слово», для сбора соответствующей частотности.
Не забудьте указать регион (если это требуется)! Регионы Yandex.Direct и регионы Yandex.Wordstat - независимые. Т.к. в данном случае программа будет обращаться непосредственно к Yandex.Direct, то и учитываться будут те регионы, которые установлены именно в этом окне, а не в регионах Yandex.Wordstat.
Нажимаем на кнопку «Получить данные».
Особенности сбора частотности с помощью Яндекс Директа:
Yandex.Direct может "склеивать" синтаксически похожие фразы в одну. Например, фразы "пластиковые окна" и "окна пластиковые" будут склеены. В результате программа не сможет записать статистику для этих фраз, потому что в отчете сервиса присутсвует только статистика для их сгруппированного варианта, а не для каждой фразы в отдельности.
Yandex.Direct принимает фразы, состоящие не более чем из 7 слов, поэтому длинные НЧ фразы проанализировать не получится.
Yandex.Direct крайне придирчив к любым символам, отличным от букв русского и английского алфавита и цифр, поэтому фразы, содержащие знаки препинания и другие спец. символы, будут проигнорированы.
Ключевые фразы в этом режиме анализируются пачками, а не поштучно. Поэтому, если в пачке фраз содержится хотя бы одна фраза, которая не удовлетворяет условиям Yandex.Direct, то вся пачка фраз отвергается с ошибкой. В таком случае, нужно просто заново нажать на кнопку парсинга. Чтобы вы видели, когда прервется парсинг, советую в нижней части Кей Коллектора перейти во вкладку «Статистика».
Если у вас не получается получить данные для всех запросов с помощью Яндекс Директа, воспользуйтесь обычным сбором частотности.
Итак, вот как выглядит алгоритм успешного и быстрого сбора семантического ядра при помощи Кей Коллектора:
1. Собираем все запросы в нише.
2. Группируем запросы по типам.
3. Делаем нужные настройки в программе для ускорения парсинга и автоматизации распознания каптчи.
4. Удаляем дубли запросов.
5. Парсим статистику запросов при помощи Яндекс Директа. Если работаем с большим списком запросов, нажимаем на кнопку обработки запросов еще несколько раз, так как в режиме парсинга через Я.Директ может прерываться работа парсинга.
6. Если не получилось собрать статистику всех запросов через Яндекс Директ, парсим ее при помощи обычного сбора частотностей «!».
Ну и теперь последнее что я хотел сказать, используйте всегда совершенно новые механизмы понимания и продвижения вашего сайта. Так я настоятельно советую воспользоваться бесплатной регистрацией в каталогах, при чём займёт это у вас 17 минут - а эффект увидите сразу! Дерзайте.
Ещё по теме:
» Категория: Маркетинг 2016 года
Каталоги и доски для регистрации



Выбери свой тариф
Доставка цветов в Семилуках среди-цветов.ру.
Новый принцип револьвера для твоего сайта

Отзывы о системе и её работе
 Начальник отдела маркетинга
Начальник отдела маркетингаАлексей
 Зам. ген. директора.
Зам. ген. директора.Артур
 Ген. директор.
Ген. директор.Михаил
Новости сервиса
Друзья, новое обновление в 2018 году трастовой базы сайтов, которое производилось вручную...
Друзья, новое обновление в 2018 году трастовой базы сайтов, которое производилось вручную...
Друзья, первое обновление в 2018 году трастовой базы сайтов, которое производилось вручную...
Регистрация в белых каталогах статей сразу в ТОП 3 Яндекса

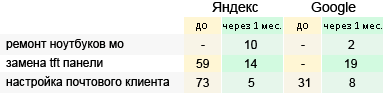
Примеры, которые лучше других показывают уровень отдачи от регистрации по нашей базе трастовых каталогов.
Преимущества нашей системы основные плюсы

А при составлении контента для подачи в трастовые каталоги, можно использовать несколько анкоров, что только повышает отдачу для вашего сайта.

Наш сервис является уникальным в своём роде, позволяя не только наращивать бэки и ТИЦ, но и за не большую плату выводить в ТОП разные запросы.

Если говорить о качестве данных каталогов, то среди прочего можно выделить ТИЦ и быстроту индексации вновь добавленных статей.

А размещение в нашей базе трастовых каталогов происходит за менее часа для 1 сайта, так как она полностью оптимизирована.
О системе
Новости системы
Зарегистрироваться
О нас
База каталогов для регистрации
Вопросы по системе
Контакты
Маркетинг 2016 года
Seo гуру
Веб ресурс
Продвижение веб сайта
Умное продвижение
Поднять ТИЦ бесплатно
Плюсы интернет рекламы
Новые виды маркетинга
Психология рекламы
Безлимитный ответ
Текст подачи объявления
Реклама на сайте





